本文由 简悦 SimpRead 转码, 原文地址 www.cnblogs.com
1|0**LPRnet 轻量级实时车牌识别**
1|1 简述 LPRnet 特点
LPRNet 由轻量级的卷积神经网络组成,所以它可以采用端到端的方法来进行训练。据我们所知,LPRNet 是第一个没有采用 RNNs 的实时车牌识别系统。因此,LPRNet 算法可以为 LPR 创建嵌入式部署的解决方案,即便是在具有较高挑战性的中文车牌识别上。
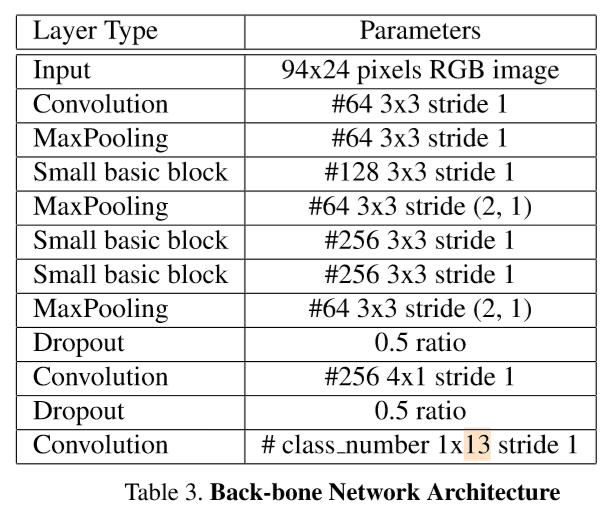
骨干网络的结构在表 [3] 中进行了描述。骨干网络获取原始的 RGB 图片作为输入,并且计算出大量特征的空间分布。*宽卷积 (113 的卷积核) 利用本地字符的上下文从而取代了基于 LSTM 的 RNN 网络**。骨干子网络的输出可以被认为是一个代表对应字符可能性的序列,它的长度刚到等于输入图像的宽度。由于解码器的输出与目标字符序列的长度是不一致的,因此采用了 CTC 损失函数, 无需分割的端到端训练。CTC 损失函数是一种广泛地用于处理输入和输出序列不对齐的方法。
1|2**LPRnet 网络结构如下表:**
small basic block 主要是 Inception 结构:

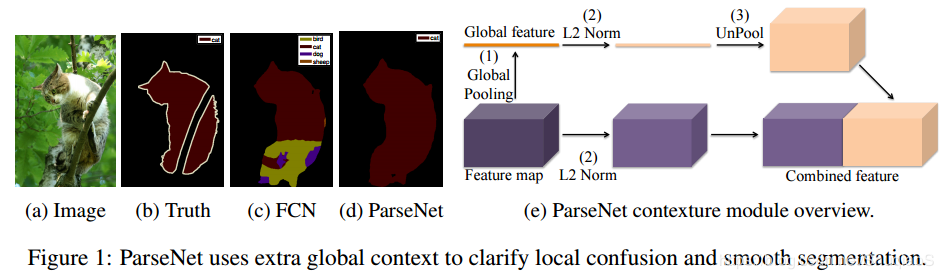
1|3 借鉴 parsenet,嵌入全局上下文特征
为了进一步地提升模型的表现,增强解码器所得的中间特征图,采用用全局上下文关系进行嵌入 [12]。它是通过全连接层对骨干网络的输出层进行计算,随后将其平铺到所需的大小最后再与骨干网络的输出进行拼接 , 加入 GAP 思想源于 Parsenet,parsenet 主要图:,右侧部分为加入 GAP 拼接到 feature map 上进行识别的表示。
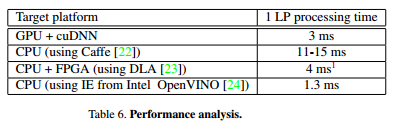
1|4 结果 -- 速度:
LPRNet 简化模型被移植到各种硬件平台,包括 CPU,GPU 和 FPGA。 结果如表 6 所示
1|5 主网络代码:
import torch.nn as nn
import torch
#定义samll_basic_block模块,借鉴Inception模块,通过1*3和3*1的卷积核来提取长宽比异常的图像特征,同时减少参数量。
class small_basic_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(small_basic_block, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(ch_in, ch_out // 4, kernel_size=1),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(3, 1), padding=(1, 0)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(1, 3), padding=(0, 1)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out, kernel_size=1),
)
def forward(self, x):
return self.block(x)
class LPRNet(nn.Module):
def __init__(self, lpr_max_len, phase, class_num, dropout_rate):
super(LPRNet, self).__init__()
self.phase = phase
self.lpr_max_len = lpr_max_len
self.class_num = class_num
self.backbone = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1), # 0
nn.BatchNorm2d(num_features=64),
nn.ReLU(), # 2
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 1, 1)),
small_basic_block(ch_in=64, ch_out=128), # *** 4 ***
nn.BatchNorm2d(num_features=128),
nn.ReLU(), # 6
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(2, 1, 2)),
small_basic_block(ch_in=64, ch_out=256), # 8
nn.BatchNorm2d(num_features=256),
nn.ReLU(), # 10
small_basic_block(ch_in=256, ch_out=256), # *** 11 ***
nn.BatchNorm2d(num_features=256), # 12
nn.ReLU(),
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(4, 1, 2)), # 14
nn.Dropout(dropout_rate),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=(1, 4), stride=1), # 16
nn.BatchNorm2d(num_features=256),
nn.ReLU(), # 18
nn.Dropout(dropout_rate),
nn.Conv2d(in_channels=256, out_channels=class_num, kernel_size=(13, 1), stride=1), # 20
nn.BatchNorm2d(num_features=class_num),
nn.ReLU(), # *** 22 ***
)
#通过1*13的异形卷积核提取特征,宽卷积(1*13的卷积核)利用本地字符的上下文从而取代了基于LSTM的RNN网络
#为了调整映射到每一个字符类的特征的深度,采用了1×1的卷积,作用等同论文中提到的(为了进一步地提升模型的表现,预增强解码器所得的中间特征图,
#采用用全局上下文关系进行嵌入。它是通过全连接层对骨干网络的输出层进行计算,随后将其平铺到所需的大小最后再与骨干网络的输出并拼接起来)
self.container = nn.Sequential(
nn.Conv2d(in_channels=448+self.class_num, out_channels=self.class_num, kernel_size=(1, 1), stride=(1, 1)),
# nn.BatchNorm2d(num_features=self.class_num),
# nn.ReLU(),
# nn.Conv2d(in_channels=self.class_num, out_channels=self.lpr_max_len+1, kernel_size=3, stride=2),
# nn.ReLU(),
)
def forward(self, x):
#保存不同层的特征,目的用于下边拼接global_context特征
keep_features = list()
for i, layer in enumerate(self.backbone.children()):
x = layer(x)
if i in [2, 6, 13, 22]: # [2, 4, 8, 11, 22]
keep_features.append(x)
#GAP提取全局平均池化特征,拼接起来送入识别container(1*1的卷积)
global_context = list()
for i, f in enumerate(keep_features):
if i in [0, 1]:
f = nn.AvgPool2d(kernel_size=5, stride=5)(f)
if i in [2]:
f = nn.AvgPool2d(kernel_size=(4, 10), stride=(4, 2))(f)
f_pow = torch.pow(f, 2)
f_mean = torch.mean(f_pow)
f = torch.div(f, f_mean)
global_context.append(f)
x = torch.cat(global_context, 1)
x = self.container(x)
logits = torch.mean(x, dim=2)
return logits
def build_lprnet(lpr_max_len=8, phase=False, class_num=66, dropout_rate=0.5):
Net = LPRNet(lpr_max_len, phase, class_num, dropout_rate)
if phase == "train":
return Net.train()
else:
return Net.eval()
EOF
本文作者:You-wh
本文链接:https://www.cnblogs.com/ywheunji/p/12268340.html
关于博主:史上最菜算法工程师,有评论看到会及时回复
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


Comments | NOTHING